回歸原點 Back to Basics
作者:周思博 (Joel Spolsky)
譯:Paul May 梅普華
Tuesday, December 11, 2001
屬於 Joel on Software, https://www.joelonsoftware.com/2001/12/11/back-to-basics/
我們在這個站花了很多時間討論讓人興奮的大局概念,像是 .NET 對 Java、XML 策略、鎖住客戶、競爭策略、軟體設計、架構等等。這所有的概念就某方面來看就像是個夾心蛋糕。最上層有軟體策略。再下來可以想想 .NET 之類的架構,然後再下面是個別的產品:像 Java 之類的軟體開發產品或 Windows 之類的平台。
請再向蛋糕下層挖下去。是 DLL 嗎?還是物件或是函數呢?都不是!再下去!下到某個地方就會想到用程式語言撰寫,一行又一行的程式。
不過還不夠深。今天我想談的 CPU。一片把位元組們搬來搬去的小矽晶片。先假裝你是個新手程式師,把你所有的程式設計和軟體還有管理知識都丟掉,然後回到最底層的馮紐曼的基本結構。暫時先把J2EE由你腦中拿掉,來想想位元組。

為什麼要這樣做呢?我認為人們所犯的某些大錯雖然錯在最高的架構層,但其實是因為不夠瞭解或想錯某些在最底層很簡單的事情。你可能建了一座雄偉的宮殿,可是地基卻是一塌糊塗。本來應該用好的水泥磚,結果卻用了碎石頭。所以宮殿看起來雖然華麗,可是浴缸卻時常移位,而你根本不知道怎麼回事。
所以今天就來個深呼吸。請跟著我來做個用 C 語言進行的小小練習吧。
記得 C 的字串用法吧:它們是由一串位元組後面接一個 null 字元(值為0)所組成。這裡有兩個明顯的暗示:
- 必須整個字串走一遍找到結尾的 null 字元,才能知道字串在哪裡結束(也就是說字串的長度)。
- 字串裡不能有任何零。所以你不能用 C 字串來儲存 JPEG 圖片之類的二進位大物件。
為什麼C字串要這樣運作呢?因為發明 UNIX 和 C 語言時用的 PDP-7 微處理器有一種 ASCIZ 字串型別。ASCIZ 意思是「用 Z(零)結尾的 ASCII。」
這是儲存字串唯一的方法嗎?並不是,事實上它是儲存字串最爛的方法之一。只要是有作用的程式、API、作業系統、類別庫,都應該像躲瘟疫一樣避開 ASCIZ 字串。為什麼呢?
讓我們由撰寫 strcat 這個把一個字串接到另一個字串的程式開始。
void strcat( char* dest, char* src )
{
while (*dest) dest++;
while (*dest++ = *src++);
}
大約讀一下這段程式,想想我們這裡做些什麼。我們先掃描第一個字串尋找結尾的 NULL 字元。找到之後再掃描第二個字串,掃描時每次把一個字元複製到第一個字串。
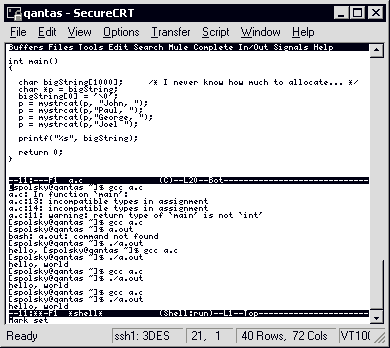
這種字串處理和字串連接對 Kernighan 和 Ritchie 來說夠好了,不過還是有些問題。舉例來說。如果你有一大堆名字,全部都要附加到一個大字串後面:
char bigString[1000]; /* 我永遠不知道要配多少記憶體 */
bigString[0] = '\0';
strcat(bigString,"John, ");
strcat(bigString,"Paul, ");
strcat(bigString,"George, ");
strcat(bigString,"Joel ");
這程式能動,對吧?沒錯,而且看起來不錯也很乾淨。
它的效能如何?是不是儘可能的快呢?它能處理更多資料嗎?如果我有一百萬個字串要連接,這樣做適合嗎?
答案是否。這段程式用了油漆工Shlemiel的演算法。Shlemiel 是誰?他是下面這個笑話的主角:
Shlemiel 得到一個在路上塗油漆的工作,他要漆在路中間的間斷分隔線。第一天他拿了一罐油漆去漆好了 300 碼的路。「做得真好!」他的老闆說「你手腳真快啊!」然後就給他一個銅板。
第二天 Shlemiel 只漆了 150 碼。「這樣啊,沒有昨天好,不過也還是很快。150 碼也很了不起。」也給他一個銅板。
第三天 Shlemiel 只漆了 30 碼。「只有 30 碼而已!」老闆就哇哇大叫了。「這實在是無法接受!第一天你漆了十倍的長度耶!究竟怎麼回事啊?」
「我也沒辦法啊,」Shlemiel 說「我每隔一天就離油漆罐愈來愈遠啊!」

(想挑戰的可以回答真實的數字是什麼?)
這個爛笑話正確地說明了使用像我剛剛寫的 strcat 版本會發生的狀況。由於 strcat 的第一段每次都必須掃描目的字串,重複地找尋可惡的結尾 NULL 字元,所以這個函數會比真正需要的時間慢上許多,而且完全不能正常處理更多的資料。你每天用的程式中很多都有這個問題。很多檔案系統的實作方式都有問題,不適合把幾千個檔案放在同一個目錄裡。因為同一個目錄裡有幾千個檔案時效率就會急速下降。試著打開一個塞滿垃圾的 Windows 資源回收桶看看有多慢 - 要花幾小時才能顯示出來,顯然並非與內含檔案數量成線性關係。裡頭某處一定有個油漆工 Shlemiel 演算法在作怪。當你發現某件事本來應該有線性的效能,實際上卻是次方的效能,就可以去找隱藏的 Shlemiel。他們常常躲在你的程式庫裡。看著一長串的 strcat 或是迴圈中的 strcat 並不會讓你立即喊出「n次方」,不過兇手就是它了。
要怎麼修正這個問題呢?有幾個聰明的 C 程式師實作了他們自己的 mystrcat,內容如下:
char* mystrcat( char* dest, char* src )
{
while (*dest) dest++;
while (*dest++ = *src++);
return --dest;
}
我們在這裡做了什麼?我們多花了一點點成本,傳回指向較長的新字串結尾的指標。如此呼叫這個函數的程式就可以選擇不必重新掃描,直接把新字串接上去:
char bigString[1000]; /* 我永遠不知道要配多少記憶體... */
char *p = bigString;
bigString[0] = '\0';
p = mystrcat(p,"John, ");
p = mystrcat(p,"Paul, ");
p = mystrcat(p,"George, ");
p = mystrcat(p,"Joel ");
這段程式的效率當然是線性而非 n 次方的,所以要連接很多東西時也不會變慢太多。
Pascal 的設計者注意到這個問題也加以「修正」了,修正的方法是在字串的第一個位元組存一個位元組數。這就叫做 Pascal 字串。Pascal 字串裡可以放零也不必用 NULL 字元結尾。因為一個位元組只能放 0 到 255 的數字,所以 Pascal 字串最長只能到255個位元組,不過由於他們不用在結尾加 NULL 字元,所以佔的記憶體和 ASCIZ 字串一樣。Pascal 字串的好處是取字串長度時不必用迴圈了。在 Pascal 裡求字串長度不用迴圈,只要一個組合組言指令就夠了。當然是快太多了。
舊的麥金塔作業系統全都是用 Pascal 字串。很多其他平台的 C 程式師也為了速度而用 Pascal 字串。Excel 內部就是用 Pascal 字串,所以 Excel 裡很多地方的字串長度最多只能到255個位元組,這也是 Excel 飛快無比的原因之一。
有很長一段時期,如果想在 C 程式裡寫一個 Pascal 字串文字,必須寫成:
char* str = "\006Hello!";
沒錯,你得自己手工算出位元組的數目,然後寫死在字串的第一個位元組。懶惰的程式師會做下面的事,結果就拖慢了程式:
char* str = "*Hello!";
str[0] = strlen(str) - 1;
注意這個例子裡用的字串既是用 NULL 字元結尾(編譯器做的)又是 Pascal 字串。我習慣稱之為fucked字串,因為這比NULL 字元結尾的 Pascal 字串好叫多了。不過這裡是普通級頻道,所以你還是用較長的名字吧。
我之前省略了一個很重要的問題。記得這一行程式嗎?
char bigString[1000]; /* 我永遠不知道要配多少記憶體... */
由於我們今天的主題是位元,所以不應該就這樣忽略它。我應該要用正確的寫法:找出需要的位元組數然後配置正確的記憶體量。
我不需要這樣做嗎?
這是一定要的。如果不做的話,某個聰明的駭客讀我的程式時會注意到,我只配置了 1000 個位元組並期望這數字足夠,他們會找出某些聰明的方法,讓我把一個長 1100 位元組的字串strcat到原本 1000 位元組的記憶體中,然後就會覆蓋堆疊框並改變返回位址,於是當這個函數返回時就會執行到駭客寫的程式。當他們說某個程式有一個緩衝區溢出漏洞時就是指這種東西。從前這可是駭客和蠕蟲侵入的頭號原因,不過微軟 Outlook 出來後,入侵就簡單到連小朋友都會做了(譯註:因為漏洞很多又可以用 VBScript 寫)。
好吧,所以說這些程式師都只是些漏洞百出的傻瓜。他們應該要算出要配置的記憶體數量才對。
不過實際上在 C 裡並不是這麼容易。讓我們回到我們的小小範例:
char bigString[1000]; /* 我永遠不知道要配多少記憶體... */
char *p = bigString;
bigString[0] = '\0';
p = mystrcat(p,"John, ");
p = mystrcat(p,"Paul, ");
p = mystrcat(p,"George, ");
p = mystrcat(p,"Joel ");
我們應該要配置多少記憶體呢?讓我們試試正確的方式。
char* bigString;
int i = 0;
i = strlen("John, ")
+ strlen("Paul, ")
+ strlen("George, ")
+ strlen("Joel ");
bigString = (char*) malloc (i + 1);
/* 記得預留結尾NULL字元的空間! */
...
我已經暈了。你可能正打算放棄去別的地方。我不怪你,不過請再忍耐一下,因為快要變得很好玩了。
我們必須把每個字串掃描一次才能算出所有字串的總長度,然後在連接字串時又要再掃描一遍。既然用 Pascal 字串時 strlen 動作會變快。或許我們可以寫一個能替我們配置記憶體的 strcat。
這時就出現另一種蠕蟲(譯註:指下面所討論的可用鏈結):記憶體配置器。你知道 malloc 的運作原理嗎?malloc 的特性是有一長串由可用記憶體組成的鏈結串列,名為可用鏈結(free chain)。當你呼叫 malloc 時會掃描鏈結串列,找尋大小滿足要求的記憶體區塊。然後把區塊切成兩塊,一塊是你所要求的大小,另一塊則是剩下的記憶體,把你要的那塊傳給你,再把另一塊(如果有的話)放回鏈結串列中。當你呼叫 free 時會把釋放的區塊加回可用鏈結。最後可用鏈結會被切割成很多小塊,當你要求大塊記憶體時就會找不到大小適合的記憶體。於是 malloc 就會逾時並開始掃描可用鏈結,嘗試把相鄰的小可用區塊合併成較大的區域。這個動作會花個三天半(譯註:就是說很慢啦)。這一團混亂的最後結論就是說 malloc 的效能特性絕不會非常快(一定要掃描可用鏈結),而且偶而(無法預測)要清理時還會慢到暈倒。(補充一下,令人驚訝的是這和 garbage collected 系統的效能特性是一樣的。所以人們說 garbage collection 的效能損失有多麼巨大,不完全是事實,因為一般的 malloc 實作都有著相同類型的效能損失,只不過稍為好一點點。)
聰明的程式師在配置記憶體時會用 2 的次方為大小(比如 4 位元組,8 位元組,16 位元組,18446744073709551616 位元組等等),讓 malloc 的潛在不隱定性降到最低。這樣可以讓可用鏈結裡小碎塊的數量降到最低,而有玩樂高積木的人應該都能直覺理解其原因。雖然似乎有點浪費空間,不過很容易就會看出浪費的空間不會超過總空間的一半。所以你的程式最多只會佔用所需空間的兩倍,這應該不是什麼大問題才對。
假設你寫了一個聰明的 strcat 函數,可以自動重新配置目的緩衝區。這個函數是否應該每次都重新配置到剛好的大小呢?我的老師兼心靈導師Stan Eisenstat 建議,當你呼叫 realloc 時每次都應該用原本配置大小的兩倍。意思是永遠不必呼用 realloc 超過 lg n 次,即使是對很大的字串來說也會有很不錯的效率特性,而且也絕不會浪費超過一半的記憶體。
總而言之,在這往下到最底層的位元組世界中,生命愈來愈混亂。現在是不是很慶幸不需要再用 C 寫程式呢?我們現在有像 Perl、Java、VB、XSLT 之類的偉大程式語言,讓你永遠都不用考慮這種事情,因為程式語言都想辦法替你處理好了。不過偶而鉛管等基礎設施還是會在客廳地板中央突出來,這時候我們就得考慮要用 String 類別還是 StringBuilder 類別,或是想想某些類似的差異,因為編譯器還不夠聰明,無法理解我們嘗試完成的每件事,也無法幫助我們不會疏忽寫出油漆工 Shlemiel 演算法。

上星期我寫過如果你的資料是以 XML 方式儲存的話,就無法實作出快速的 SQL 敘述 SELECT author FROM books。為了避免有人不懂我在說什麼,我再強調一次今天整天都在講 CPU 層次的事。這樣子應該比較看得懂上面的意思吧。
一個關聯式資料庫會如何實作 SELECT author FROM books 呢?在關聯式資料庫中,資料表的每一行(舉例來說是books資料表)的位元組數都完全相同,而且各個欄位由列開頭起算的偏移量都是固定的。所以舉個例子來說,如果books資料表中每個記錄的長度都是 100 個位元組,而author欄是位於偏移量23的地方,那麼各個作者就會存在第 23, 123, 223, 323 等位元組的位址。在這個 SQL 查詢中要移到下一個記錄時要怎麼做呢?基本上只要這樣就好:
pointer += 100;
只要一個CPU指令。夠快了吧。
現在讓我們來看看用XML格式儲存的books資料表。
<?xml 廢話....>
<books>
<book>
<title>UI Design for Programmers</title>
<author>Joel Spolsky</author>
</book>
<book>
<title>The Chop Suey Club</title>
<author>Bruce Weber</author>
</book>
</books>
來個小問題。要移到下一個記錄的程式要怎麼寫?
呃...
這時候一個好的程式師可能會說,好吧,讓我們分析 XML 轉成樹狀結構存在記憶體裡,這樣處理起來會相當快。不過這時候 CPU 要處理SELECT author FROM books所做的工作量絕對會無聊到讓你哭出來。每個編譯器作者都知道字彙和語法分析是編譯過程中最慢的部份。簡單的說,字彙分析和語法分析時牽涉到大量的字串處理(前面已經發現這是很慢的)和大量的記憶體(也是已知很慢的),然後還要在記憶體中建立一個抽象文法樹。而且還要假設你擁有足夠的記憶體可以一次載入所有資料。在關聯式資料庫中,在記錄間移動的速度是固定的,而且實際上只要一個 CPU 指令。這是刻意設計出來的。另外利用記憶體映對檔案,就只要把真正要用的資料由載入對應的磁碟區塊即可。在用 XML 的時候,如果有作前處理預先分析,在記錄間移動的速度也是固定的,不過需要大量的啟動時間,如果不預先分析,那麼在記錄間移動的速度就要看之前的記錄有多長了,而且不管怎麼都要幾百個 CPU 指令。
對我來說,這表示當資料量很大又要求速度時不能用 XML。如果資料不多或做的事並不需要速度,XML 是個不錯的格式。如果你想魚與熊掌兼得,就得想個方法在 XML 以外加些詮釋資料(metadata),儲存類似 Pascal 字串中位元組數目的資料。這樣能提示資料在檔案中的位址,就不需要再去掃描分析了。不過當然不能用文字編輯器去編輯檔案了,因為會把詮釋資料弄亂,所以其實這也不能算上真正的 XML 了。
對於那些一直跟著我撐到這裡的讀者,我希望你已經學到或是重新思考了某些事情。我希望探討像 strcat 和 malloc 究竟如何運作這種枯燥的電腦科學一年級課程,能在你面對 XML 等技術時,協助你思考最新的高層次策略與架構上的決策。至於今天的作業,可以想想為什麼全美達(Transmeta)的晶片好像總是賣不好。或者想想為什麼最早HTML 規格的 TABLE 設計會爛到讓撥接上網的人不能快速的顯示大型表格。也可以想想 COM 既然這麼快,為什麼跨越行程邊界時又快不起了。或者 NT 設計者為什麼會把顯示驅動程式放入核心空間而不留在使用者空間呢。
這所有的問題都需要你考慮位元組的層次,而它們也影響到我們在各種架構和策略上所做整體而高層次的決策。我認為電腦科系一年級學生應該由基礎開始學起,使用 C 並由 CPU 開始一路建立觀念,這正是原因。很多電腦科學計劃認為 Java 很「容易」,不用碰無聊的字串/記憶體配置就能學習最酷的物件導向技術,能讓你的大程式更加模組化,所以很適合當作入門學習的電腦語言。我對這種想法其實非常的反感。這是一個蘊釀中的教學災難。畢業生一代代下來會愈來愈墮落,到處寫出油漆工 Shlemiel 演算法而完全不自知,因為他們完全不知道,雖然 perl 指令看不出來,但是字串的底層操作其實是很困難的。如果你想把某人教好,就得從最底層開始。就像電影「小子難纏」一樣。不斷的上蠟打蠟。三個星期後輕輕鬆鬆就把別的小鬼幹掉了。
這些網頁的內容為表達個人意見。
All contents Copyright © 1999-2006 by Joel Spolsky. All Rights Reserved.